KAfka In detail

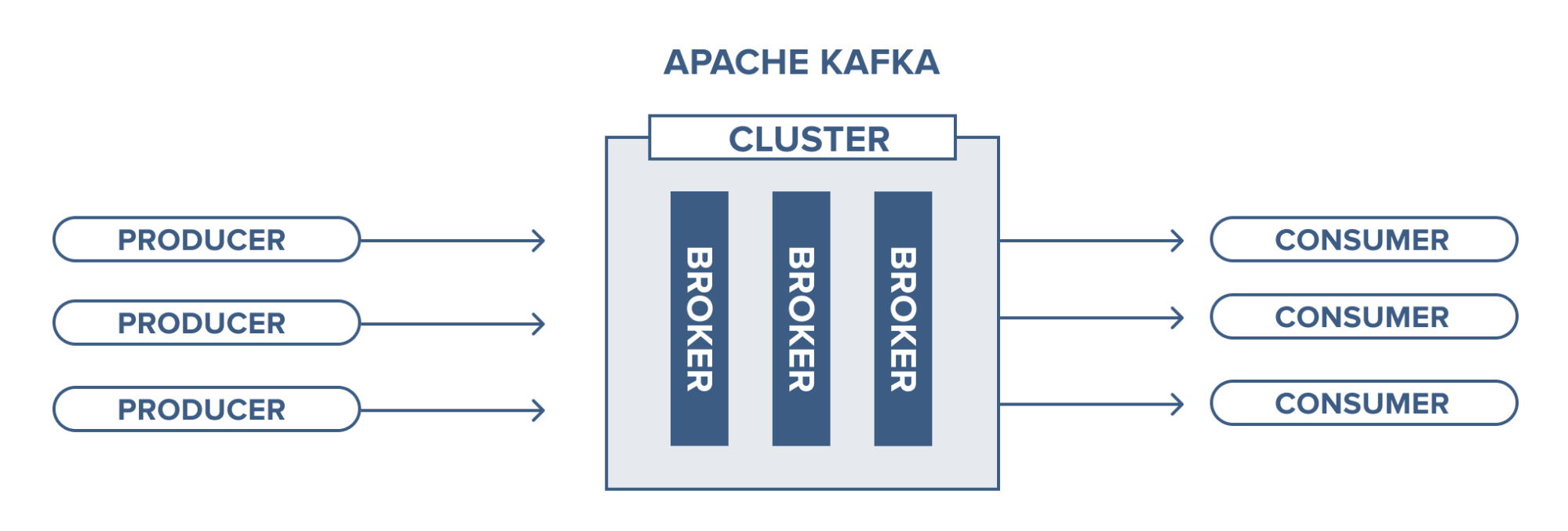
Following are a few benefits of Kafka −
Reliability − Kafka is distributed, partitioned, replicated, and fault tolerance.
Scalability − Kafka messaging system scales easily without downtime.
Durability − Kafka uses a
Distributed commit log
which means messages persists on disk as fast as possible, hence it is durable..Performance − Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even many TB of messages are stored.
Kafka is very fast and guarantees zero downtime and zero data loss.
Use Cases
Kafka can be used in many Use Cases. Some of them are listed below −
Metrics − Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Log Aggregation Solution − Kafka can be used across an organization to collect logs from multiple services and make them available in a standard format to multiple consumers.
Stream Processing − Popular frameworks such as Storm and Spark Streaming read data from a topic, processes it, and write processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.


Comments
Post a Comment